최근에 면접을 보면서 들었던 질문이기도 하고 TDD 미션을 진행하면서 코딩할 때도 궁금증이 생겨서 위 제목에 관한 내용을 정리해보려고 합니다.
정리하기에 앞서 간략히 컬렉션 프레임워크에 대해 짚고 넘어가도록 하겠습니다.
컬렉션 프레임워크에서는 컬렉션 데이터 그룹을 크게 3가지 타입이 존재한다고 인식하고 각 컬렉션을 다루는데 필요한 기능을 가진 3개의 인터페이스를 정의하였다. 그리고 인터페이스 List와 Set의 공통된 부분을 다시 뽑아서 새로운 인터페이스인 Collection을 추가로 정의하였다.
- Java의 정석 3판 中 -

3개의 인터페이스는 위 사진과 같습니다.
List
- 순서가 있는 데이터의 집합. 데이터 중복을 허용한다.
- 구현클래스 : ArrayList, LinkedList, Stack, Vector 등
Set
- 순서를 유지하지 않는 데이터의 집합, 데이터의 중복을 허용하지 않는다.
- 구현클래스 : HashSet, TreeSet 등
Map
- 키(key)와 값(value)의 쌍(pair)으로 이루어진 데이터의 집합
- 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값은 중복을 허용한다.
- 구현클래스 : HashMap, TreeMap, Hashtable 등
각 인터페이스의 특징과 차이를 잘 이해하고 있어야 합니다. 이번 장에서는 아~ 컬렉션 프레임워크에는 3개의 핵심 인터페이스가 있구나~ List 인터페이스를 구현한 ArrayList와 LinkedList에 관한 내용을 정리한 글이겠구나~로 이해하시면 될 거 같습니다.
List 인터페이스
중복을 허용하면서 저장순서가 유지되는 컬렉션을 구현하는 데 사용!!
다양한 메서드가 있지만 사용하시면서 알아 가는 것이 더 기억에 오래 남기 때문에 여기서 정리하지는 않겠습니다.
ArrayList 클래스 (구현체!)
ArrayList는 List 인터페이스를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용하는 특징을 자연스럽게 가지고 있습니다.
ArrayList는 기존의 Vector를 개선한 것으로 Vector의 구현원리와 기능적인 측면에서 동일하다고 할 수 있다. Vector는 기존에 작성된 소스와의 호환성을 위해서 계속 남겨 두고 있을 뿐이기 때문에 가능하다면 Vector보다는 ArrayList를 사용하자.
- Java의 정석 中
ArrayList의 특징
- Object 배열을 이용해서 데이터를 순차적으로 저장
=> 0번째, 1번째, ... n번째
- 배열에 더 이상 저장할 공간이 없으면 보다 더 큰 새로운 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장된다.
그럼 조금 더 상세하게 내용을 알아봅시다. 저희가 처음 코딩을 배우고 배열을 사용할 때 꼭 배열의 크기를 미리 알려줬어야 합니다. 근데 ArrayList를 사용하신 분들이라면 다음 처럼 ArrayList의 크기를 알려주지 않고 new로 인스턴스를 생성하기만 합니다.
ArrayList 내부로 들어가보면 생성자에 다음과 같이 구현되어 있습니다.


private List<Integer> numbers = new ArrayList<>(); // capacity is ten
위 특징처럼 10개 이상의 아이템을 배열에 저장한다면? 내부적으로 더 큰 배열로 바꿔치기 할 겁니다. 다만 이런 기능에는 코스트가 들기 때문에 ArrayList에 들어올 수 있는 아이템의 크기가 어떻게 될 지 예측을 해보는 것이 좋아 보입니다.
물론 배열이기 때문에 인스턴스를 생성할 때 크기를 아래처럼 줄 수도 있습니다.
private List<Integer> numbers = new ArrayList<>(10);
또 하나의 특징이 있는데, 중간에 있는 값을 삭제할 때 코스트가 발생합니다.
numbers에 1, 2, 3, 4가 있다고 가정해보면
numbers.remove(2)를 할 수 있습니다. (여기에서 2는 index기 때문에 숫자 3이 삭제가 됩니다.)
그렇다면 다음과 같은 작업을 수행하게 됩니다.
- 1, 2, 3, 4, null, null, ... null [10개가 있습니다.]
- 1, 2, 4, 4, null, null, ... null [삭제할 데이터의 아래에 있는 데이터를 한 칸씩 위로 복사해서 삭제할 데이터를 덮어씁니다.]
이 부분에서 데이터를 복사할 때 System.arraycopy()를 사용합니다.
- 1, 2, 4, null, null, ... null [데이터가 모두 한 칸씩 위로 이동하였으므로 마지막 데이터는 null로 변경해야 합니다.]
1, 2, 4, 4, null, null, ... null일 때 4가 한 칸 위로 올라갔기 때문에 마지막 데이터인 4는 이동하였으므로 null로 해주는 겁니다
- 데이터가 삭제되어 데이터의 개수가 줄었으므로 size의 값을 1 감소시킵니다.
배열의 중간에 위치한 객체를 추가하거나 삭제하는 경우 System.arraycopy()를 호출하여 데이터의 위치를 이동시켜 줘야 하기 때문에 데이터가 정말 많다면 코스트가 어마무시할 겁니다.
LinkedList 클래스 (구현체!)
배열은 구조가 간단하고, 사용하기 쉽고, 데이터를 읽어오는데 걸리는 시간이 가장 빠르다는 장점을 가지고 있지만 다음과 같은 단점을 가지고 있습니다.
1. 크기를 변경할 수 없다.
- 물론 ArrayList 내부적으로 더 큰 배열로 복사를 하지만 이 행위도 코스트가 많이 소요됩니다.
2. 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
- 위 ArrayList의 삭제처럼 중간에 있는 데이터를 삭제하고자 한다면 코스트가 많이 소요됩니다.
이러한 배열의 단점을 보완하기 위해 링크드 리스트라는 자료구조가 나타난 것입니다.
LinkedList 내부를 살펴보면 다음과 같습니다.


링크드 리스트는 한 Node(요소)에 다음 Node의 참조(주소값)와 데이터로 구성되어 있습니다. 그래서 Node와 Node간의 연결을 참조를 통해 하고 있기 때문에 데이터의 삽입과 삭제가 간단합니다.
위 Node는 next, prev를 통한 양방향 참조를 하고 있지만 여기서는 단방향 참조라고 생각하고 예시를 들겠습니다.
private List<Integer> numbers = new LinkedList<>();
ArrayList와 마찬가지로 number에 1, 2, 3, 4가 있다고 가정해보면 LinkedList는 다음과 같이 표현할 수 있을 거 같습니다.

여기서 2와 3 사이에 데이터를 추가하려면? 다음과 같이 작업을 하게 됩니다.
- Node 5 생성

- Node 2는 Node 5를 참조하도록 수정
- Node 5는 Node 2가 참조하던 Node 3을 참조하도록 수정

그럼 여기서 다시 Node 5를 삭제한다고 하면? 다음과 같이 작업을 하게 됩니다.
- Node 5가 next로 참조하고 있던 3의 주소를
- Node 5를 참조하고 있던 Node 2가 참조하도록 바꿉니다.
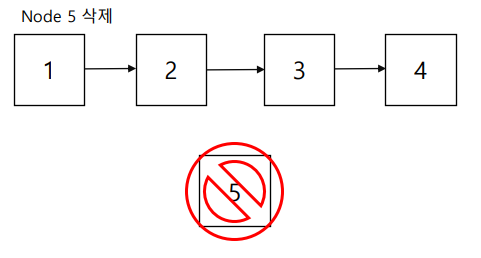
위와 같은 참조의 수정을 통해서 삽입과 삭제를 내부적으로 처리하기 때문에 ArrayList의 단점이었던 부분을 LinkedList를 사용하면 빠르게 처리할 수 있습니다.
ArrayList, LinkedList의 특장점을 정리하고 마무리하도록 하겠습니다.
ArrayList
읽기: 빠르다
추가/삭제: 느리다
(순차적인 추가삭제는 더 빠름)
LinkedList
읽기: 느리다
추가/삭제: 빠르다
(데이터가 많을수록 접근성이 떨어짐)
이 이후부터는 저를 위한 정리입니다~!
List vs ArrayList
- List = 인터페이스
- ArrayList = 구현체
List<Integer> list = new ArrayList<>();
ArrayList<Integer> arrayList = new ArrayList<>();
위 두 개의 코드 모두 정상 작동 하는데 무엇이 다른가??
List를 사용하는 경우는 "로미오"라는 역할을 공통 인터페이스로 추출하여 "장동건", "현빈", "원빈"이라는 배우들이 연기(구현)를 하는 것이라 생각이 됩니다.
ArrayList를 사용하는 경우는 "로미오"라는 역할에 "장동건"만이 연기(구현)를 하는 것이라 생각이 됩니다.
이 부분은 영한님의 "스프링 핵심 원리"를 들으신 분들이라면 이해가 빠르게 되실거라 생각됩니다. 역할과 책임의 분리라던지, 역할(인터페이스)에 의존해야 한다, 스프링 관점에서는 DI, 유연성, 다형성에 대해 생각해볼 수 있을 거 같습니다.
Collection, List의 remove()
remove에는 Object o 혹은 int index를 매개변수로 담을 수 있는데, Object o는 Collection 인터페이스의, int index는 List 인터페이스의 메소드입니다.
만약 위 예시처림 Integer를 타입으로 가지는 numbers의 경우에는 remove(1)을 하게 되어도 Collection의 remove를 할 수는 없습니다. index에 접근해서 삭제하는 것만 가능하죠.
그런데 String 타입을 가지는 List라면 strs.remove(1)과 strs.remove("1")은 서로 다른 일을 수행할 것입니다.
'Java' 카테고리의 다른 글
| [Java] 왜 함수형 프로그래밍을 배워야 하는가? (1) | 2022.04.22 |
|---|