Spring Security를 사용한 프로젝트에서 권한에 계층을 두도록 설계했습니다. 계층을 부여하는 Entity는 Self Reference 하였고, 제가 만든 클래스에 ApplicationRunner 인터페이스를 상속하여 애플리케이션이 구동될 때 DB에서 값[권한 계층 정보]을 읽어 세팅하도록 하였습니다. 근데 애플리케이션이 구동되는 시점에 권한 계층 관련한 쿼리가 여러 번 나가는 것을 확인하여 튜닝했고 거기서 배운 것들을 정리해보도록 하겠습니다.
[Spring Security에 대한 내용은 제외하고, JPA에서 Entity가 자신을 참조하는 Self-Reference, @JoinColumn의 속성인 referencedColumName을 제대로 숙지하지 못하여 생긴 삽질]
프로젝트 버전
- 개발 도구: IntelliJ Ultimate
- Spring Boot: 2.5.7
- Java 11
- h2 Database
- Spring Data JPA 의존성 추가 [build.gradle]
- JUnit 5
권한 계층(RoleHierarchy) Entity를 사용하여 예제를 진행하도록 하겠습니다.
쿼리가 여러 번 나갔던 초기 RoleHierarchy Entity는 다음과 같습니다.
RoleHierarchy
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString(of = {"id", "name"})
public class RoleHierarchy implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "parent_name", referencedColumnName = "name")
private RoleHierarchy parent;
@OneToMany(mappedBy = "parent")
private Set<RoleHierarchy> roleHierarchySet = new HashSet<>();
@Builder
public RoleHierarchy(String name, RoleHierarchy parent) {
this.name = name;
this.parent = parent;
}
}
DB에는 다음과 같이 데이터가 저장되어 있습니다.
ROLE_HIERARCHY TABLE

위와 같이 Entity Class가 설계되어 있고, DB에 데이터가 들어가 있으면 Spring Security에 권한 계층을 적용하기 위해서 findAll()을 해야 됩니다. 그리고 findAll()을 통해 조회한 정보를 아래와 같이 자신의 부모를 좌측에, 본인은 우측에 두는 String을 만들어줍니다. 그리고 \n을 중간에 넣어 개행을 해줍니다.
ROLE_ADMIN > ROLE_MANAGER \n
ROLE_MANAGER > ROLE_USER \n
ROLE_USER > ROLE_ANYONE \n
JPQL을 사용하여 DB에 있는 데이터를 전부 조회하겠습니다.
@Slf4j
@SpringBootTest
@Transactional
@Rollback(value = false)
public class RoleHierarchyTest {
@PersistenceContext
private EntityManager em;
@Test
@Transactional
public void findAllTest() {
List<RoleHierarchy> results =
em.createQuery("select rh from RoleHierarchy rh", RoleHierarchy.class)
.getResultList();
results.iterator().forEachRemaining(roleHierarchy -> {
log.info("roleHierarchy : {}", roleHierarchy);
});
}
}
findAllTest를 실행해보면 다음과 같은 쿼리가 실행됩니다.
쿼리를 살펴보면 첫 번째 쿼리에는 JPQL로 짰던 모든 RoleHierarchy를 조회하는 예상된 쿼리가 수행되는 것을 알 수 있습니다. 그런데 2, 3, 4번째 쿼리를 보면 where 절을 사용하여 특정 RoleHierarchy를 조회하는 예상하지 못한 쿼리가 수행되는 것을 알 수 있습니다. 그리하여 다음과 같은 순서로 문제가 무엇인지를 파악하고 해결하였습니다.
- 가장 먼저 로그를 찍었습니다. JPQL이 실행되기 전과 후, 엔티티 그래프 탐색 전과 후에 로그를 찍어서 정확히 언제 쿼리가 수행되는지 확인했습니다.
- N + 1의 느낌이 나기 때문에 fetch join을 사용하였습니다. [근데 1번에서 로그를 찍었을 때, 엔티티 그래프를 조회하는 시점이 아닌 즉시 로딩과 같이 JPQL로 전체 조회를 하면서 바로 쿼리가 수행되었다.]
- Self Reference에 대한 설정이 잘못됐을 수 있기 때문에 RoleHierarchy Entity 코드를 유심히 봤으며 처음 사용하는 @JoinColumn의 속성인 "referencedColumnName"을 붙였다 떼어봤습니다.
- 그 후에 영한님 강의 QnA에 검색하여 Self Reference 관련 정보를 획득하였습니다.
1. 로그 찍기
@Test
@Transactional
public void findAllTest() {
log.info("Before Query");
List<RoleHierarchy> results =
em.createQuery("select rh from RoleHierarchy rh", RoleHierarchy.class)
.getResultList();
log.info("After Query");
results.iterator().forEachRemaining(roleHierarchy -> {
log.info("roleHierarchy : {}", roleHierarchy);
});
log.info("Select END");
}다음과 같이 JPQL이 수행되기 전, 후, for문 이후에 로그를 남깁니다.

로그에서 볼 수 있다시피 RoleHierarchy Entity에 접근하기 이전. 즉, JPQL에서 바로 쿼리가 수행되는 것을 알 수 있었습니다.
비록 위의 로그를 보면 RoleHierarhcy의 엔티티 그래프 탐색할 때 Lazy Loading 되어 1 + N 문제인 것은 아니지만, 모든 가능성은 열어두고자 fetch join을 사용해봤습니다.
2. fetch join 사용하기
@Test
@Transactional
public void findAllTest() {
log.info("Before Query");
List<RoleHierarchy> results =
em.createQuery("select distinct rh from RoleHierarchy rh " +
"left join fetch rh.roleHierarchySet", RoleHierarchy.class)
.getResultList();
log.info("After Query");
results.iterator().forEachRemaining(roleHierarchy -> {
log.info("roleHierarchy : {}", roleHierarchy);
});
log.info("Select END");
}위 처럼 left join fetch를 통해 Set<RoleHierarchy>를 한 번에 찾아오면 수정되지 않을까 했습니다.
그러나 이유를 "에라 모르겠다" 전략은 생각한대로 쉽게 통하지 않았습니다.

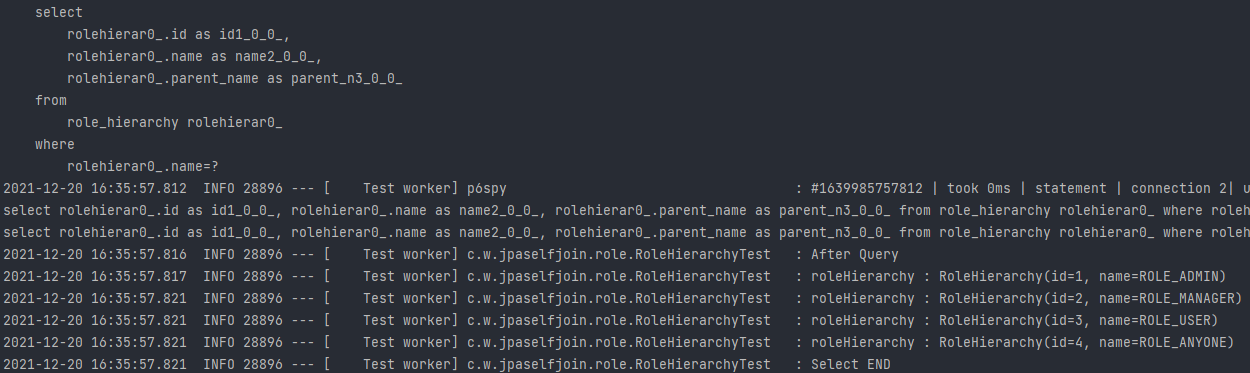
위 사진처럼 left fetch join은 정상적으로 수행된 것을 알 수 있지만, 똑같이 예상하지 못한 쿼리가 지속적으로 수행됨을 확인했습니다.
3. referencedColumnName?
그래서 이제는 RoleHierarchy Entity 자체에 의심을 품기 시작했습니다. 많이 봐왔던 어노테이션과 다르게, @JoinColumn의 속성 중 하나인 referencedColumnName은 제게는 생소했습니다. 그래서 지운 후에 findAllTest() 코드를 수행해봤습니다. 그러나 결과는 동일하게 쿼리가 나아갔습니다.
4. 영한님 QnA
그래서 Self Reference에 대한 지식이 부족함을 깨닫고 인프런 영한님 강의에 저와 같은 문제에 봉착한 다른 교육생분이 계실 거 같아서 Self Reference에 관해서 QnA를 조사했습니다. 다른 교육생분이 Self Reference에 관해 질문을 하셨고(제 예상대로 있었습니다!) 영한님께서 피드백해주신 내용도 보고 코드도 봤지만, 제가 RoleHierarchy에 적용한 Self Reference와 같았습니다. 단 하나만 빼고요. referencedColumnName 바로 이놈 말이죠. 그래서 referencedColumnName을 지우고 DB에 있는 RoleHierarchy Table을 날리고 다시 findAllTest()를 수행했습니다. 그러니깐 예상하지 못한 쿼리가 사라졌습니다.
■ 해결된 이유는?
4번을 진행해본 결과 RoleHierarchy의 Table은 다음과 같았습니다.
ROLE_HIERARCHY TABLE
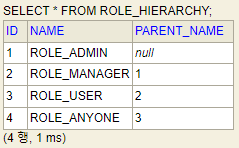
오잉? 원래는 Entity의 이름이 들어가있던 Column에 Entity의 PK인 ID 값이 들어가있었습니다. 여기서 왜 추가적인 쿼리가 수행됐는지 알 수 있었습니다.
▶ referencedColumnName은 말 그대로 참조하는 Column의 이름을 부여하는 속성이었던 것입니다. 그리고 @JoinColumn인 parent에 referencedColumnName 속성을 "name"으로 처음에 부여하였기 때문에 Entity의 name이 들어가게 된 것이죠. 그리고 이 속성이 생략되면 default로 Entity의 PK인 ID가 들어가게 됩니다.
■ 그러면 name일 경우는 추가적인 쿼리가 발생하고, ID일 경우는 추가적인 쿼리가 발생하지 않는지?
JPA의 1차 캐시가 된 것이 아닐까 싶습니다. JPQL로 모든 데이터를 조회할 때 JPA는 각 Entity를 영속성 컨텍스트에 올려둔 상태입니다. 그렇기에 @ManyToOne, @JoinColumn의 어노테이션을 가진 RoleHierarchy parent는 DB에서 찾을 필요 없이 영속성 컨텍스트에서 가져오면 됩니다. (왜? parent도 RoleHierarchy 타입이기 때문에 이미 findAll 했을 때 영속성 컨텍스트에 정보가 있기 때문이죠.)
그렇다면, name으로 설정했다면? 당연히 추가적인 쿼리가 실행되어야 합니다. JPA 입장에서는 ID로 엔티티를 구분하지 name으로는 해당 엔티티가 무엇인지를 알 수는 없으니깐요. 그래서 예상하지 못한 쿼리도 where name으로 특정 엔티티를 찾는 쿼리가 수행된 것입니다.
■ 3번에서 referencedColumnName을 지웠음에도 똑같이 예상하지 못한 쿼리가 수행된 이유는?
▶ 제가 spring.jpa.hibernate.ddl-auto의 설정을 update로 해뒀기 때문에 @JoinColumn referencedColumnName의 멤버 변수인 parent가 갱신되지 않은 것입니다. parent_name 이라는 이름으로 컬럼이 이미 존재했기 때문이죠. 그래서 별 다른 수정 없이 Entity의 name을 참조하는 것으로 유지가 되었던 것입니다.
느낀 점
JPA 뿐만 아니라 모든 기술을 사용하고 적용할 때 왜? 라는 의문과 해당 기술이 작동하는 원리를 명확하게 이해하고 사용해야 될 것 같습니다. 또한, 영한님이 강의 중에서 언급하셨던 내용을 다시금 회상하는 좋은 계기였습니다.
"JPA는 100% 이해를 하고 사용해야 합니다."
'Spring > Spring Data JPA' 카테고리의 다른 글
| Spring Data JPA - 데이터 뻥튀기 (일대다 관계 조인) (0) | 2022.03.07 |
|---|---|
| Spring Data JPA - 상속(Inheritance) + 다대다(N:M) 관계 (0) | 2022.01.09 |
| Spring Data JPA - N + 1 문제 ② 해결 방법 (0) | 2021.12.02 |
| Spring Data JPA - N + 1 문제 ① (0) | 2021.11.29 |
| Spring Data JPA - Auditing (0) | 2021.11.28 |



