"N + 1 문제 ②편"에서 N + 1 문제 해결 방법으로 Fetch Join을 사용해야 한다고 정리했었는데요. 정리를 하면서 "컬렉션 페치 조인, 일대다 관계인 @OneToMany로 연관관계를 가지는 Entity를 조회할 때 데이터 뻥튀기가 일어난다."라고 말씀드렸습니다. 그래서 오늘은 fetch join에 대해 자세히 알아보고 데이터 뻥튀기를 해결해보도록 하겠습니다.
먼저 페치 조인의 특징, 일반 조인과의 차이점을 알아보고, [일대다 관계 조인, 컬렉션 페치 조인]에 대해서 알아보도록 하겠습니다.
페치 조인의 특징
- SQL 조인 종류 X
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
일반 조인과의 차이점
- 일반 조인 실행 시 연관된 엔티티를 함께 조회하지 않음
- JPQL은 결과를 반환할 때 연관관계를 고려하지 않고, 단지 SELECT 절에 지정한 엔티티만 조회함
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩)
- 페치 조인은 객체 그래프를 SQL 한 번에 조회하는 개념
출처: https://www.inflearn.com/course/ORM-JPA-Basic (인프런 - 자바 ORM 표준 JPA 프로그래밍 - 기본편 : 김영한님)
컬렉션 페치 조인
- 일대다 (*ToMany) 조인, 컬렉션 페치 조인을 하게 되면 데이터 뻥튀기가 발생합니다.
- 뿐만 아니라 컬렉션 페치 조인은 페이징이 불가능합니다.
- 데이터 뻥튀기를 해결하기 위해서 distinct를 사용해줍니다. (즉시 로딩)
- 데이터 뻥튀기를 방지하고 페이징도 가능한 방법은 hibernate.default_batch_fetch_size, @BatchSize를 사용합니다. (지연 로딩)
글보다 코드로 보는 것이 더 와닿기 때문에 코드를 통해 확인해보도록 하겠습니다. 이번 예시도 마찬가지로 Member, Team을 사용하겠습니다.
Member는 하나의 Team에 속할 수 있으며, Team은 여러 명의 Member를 가질 수 있습니다. 이번 테스트에서는 모든 Team을 조회하고 각 Team에 있는 Member를 조회해보도록 하겠습니다.
MemberTest
@Slf4j
@SpringBootTest
class MemberTest {
@Autowired
EntityManager em;
@Test
@Transactional
@Rollback(value = false)
public void memberAnTeamTest() {
Member wangtak = new Member(1L, "wangtak@gmail.com", "왕탁이");
Member admin = new Member(2L, "admin@gmail.com", "관리자");
Member manager = new Member(3L, "manager@gmail.com", "매니저");
Member user = new Member(4L, "user@gmail.com", "사용자");
Member anonymousUser = new Member(5L, "anonymous@gmail.com", "익명");
em.persist(wangtak);
em.persist(admin);
em.persist(manager);
em.persist(user);
em.persist(anonymousUser);
Team teamA = new Team(1L, "팀A");
Team teamB = new Team(2L, "팀B");
em.persist(teamA);
em.persist(teamB);
wangtak.addTeam(teamA);
admin.addTeam(teamA);
manager.addTeam(teamA);
user.addTeam(teamB);
anonymousUser.addTeam(teamB);
em.flush();
em.clear();
List<Team> resultList = em.createQuery("select t from Team t " +
"join fetch t.members", Team.class)
.getResultList();
resultList.forEach(team -> {
System.out.println("===== team " + team + " =====");
team.getMembers().forEach(System.out::println);
});
assertThat(resultList.size()).isEqualTo(2);
}
}
테스트 코드를 봤을 때 이 테스트는 무리 없이 통과할 거처럼 보입니다. 그러나 실행해보면 실패합니다. 다음과 같은 출력문과 이유로 말이죠.

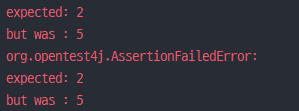
위 테스트 코드에서 teamA(팀A), teamB(팀B)라는 Team 엔티티를 2개 생성하여 DB에 Insert 했습니다. JPQL로 조건절(where) 없이 전체 Team 엔티티를 조회했기 때문에 JPQL의 결과로 나오는 Team List의 크기(teamA, teamB)는 2가 되어야 합니다. 그래서 테스트 결과의 예상은 2었지만, 실제론 5였기 때문에 테스트가 실패했다고 알려줍니다. 숫자 5는 Member 엔티티의 개수가 5개였기 때문에 나온 숫자이며 컬렉션 join fetch로 인해 이 같은 결과가 나왔습니다. 이게 바로 일대다 관계의 컬렉션 페치 조인 시 발생하는 데이터 뻥튀기입니다.
데이터 뻥튀기를 해결하기 위해서는 2가지 방법이 있습니다.
- distinct 사용하기 - 즉시 로딩, 페이징 불가능
- hibernate.default_batch_fetch_size, @BatchSize 사용하기 - 지연 로딩, 페이징 가능
distinct를 사용하는 방법은 memberAndTeamTest에 있는 JPQL에 다음 코드처럼 distinct를 넣어주면 끝이 납니다.
List<Team> resultList = em.createQuery("select distinct t from Team t join fetch t.members", Team.class)
.getResultList();
distinct를 사용하기만 했는데, 테스트 코드는 성공한 것을 볼 수 있으며 출력문 또한 저희가 원하는 대로 나오는 것을 알 수 있습니다.

요구사항에서 페이징 기능이 필요 없으면 distinct를 사용하면 됩니다. 그러나 앞서 언급했듯이 컬렉션 페치 조인은 페이징이 불가능합니다. distinct 또한 페이징이 불가능합니다. 1:N에서 1(일)을 기준으로 페이징을 하는 것이 목적인데 데이터는 N(다)를 기준으로 row, result가 생성됩니다. 저희는 Team을 기준으로, 총 몇 개의 Team이 존재하는지가 궁금한 것인데, Member를 조인하게 되면 Member Entity의 개수가 기준이 되어버립니다.
데이터 뻥튀기도 방지하고 페이징도 가능한 방법은 2번째 방법인 hibernate.default_batch_fetch_size 혹은 @BatchSize를 사용하는 것입니다. hibernate.default_batch_fetch_size는 global로 설정을 하는 것이며 @BatchSize는 local로 설정하는 방법입니다.
적용하는 방법은 아주 간단합니다. hibernate.default_batch_fetch_size는 application.yml(혹은 application.properties)에 다음 구문을 넣어주면 됩니다.
spring:
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
default_batch_fetch_size: 100
format_sql: true
@BatchSize를 적용하려면 Team 엔티티에 있는 @OneToMany 관계인 members에 다음처럼 설정해주시면 됩니다.
@BatchSize(size = 100)
@OneToMany(fetch = FetchType.LAZY, mappedBy = "team")
private List<Member> members = new ArrayList<>();
그러면 설정이 정상적으로 됐는지, 또 정상적으로 됐을 때 어떤 쿼리문이 나가고 어떤 방식으로 작동하는지 확인해보도록 하겠습니다. memberAndTeamTest에서 join fetch와 distinct를 빼주기만 하면 됩니다.
List<Team> resultList = em.createQuery("select t from Team t", Team.class)
.getResultList();
출력 결과 확인해보면 다음과 같습니다.
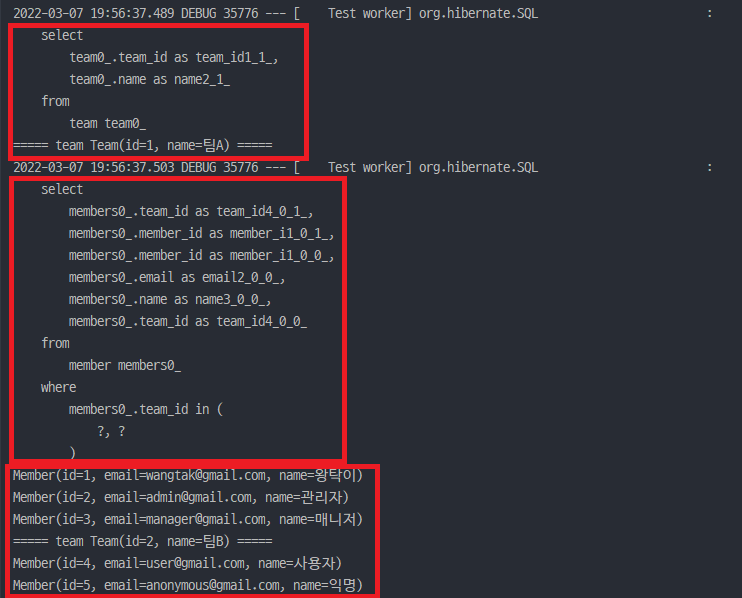
첫 번째 빨간 박스는 모든 Team 엔티티를 조회하는 쿼리가 실행됩니다. 그리고 조회한 Team의 정보가 출력이 됩니다.
두 번째 빨간 박스를 주목해야 합니다. 아까와는 좀 다른 쿼리가 실행됐습니다. 그 중심에는 where ... in ... 구문이 있습니다. 먼저 저희는 distinct를 적용할 때와는 다르게 JPQL에 fetch join을 사용하지 않았습니다. 그래서 첫 번째 빨간 박스의 쿼리만으로는 Member 엔티티의 정보를 알지 못하는 상황이며, fetch 전략은 기본적으로 지연 로딩의 방식을 사용한다고 말씀드렸기 때문에 필요로 하는 데이터에 접근했을 때 쿼리가 실행됩니다. 바로 저희가 작성한 Member의 출력 구문인 team.getMembers().forEach(System.out::println);을 만났을 때 말이죠.
또한 where ... in ... 구문은 저희가 default_batch_fetch_size를 적용했기 때문에 사용된 구문입니다. 만약 저희가 이것을 적용하지 않았더라면 어떻게 됐을까요? teamA(팀A)에 속한 멤버를 찾기 위한 쿼리 1번, teamB(팀B)에 속한 멤버를 찾기 위한 쿼리 1번 이렇게 총 2번의 쿼리를 만났을 겁니다. 바로 1 + N 문제에 직면하게 되는 거죠. 그러나 저희가 default_batch_fetch_size를 적용함으로써 페이징 처리와 지연 로딩으로 인해 발생하는 1 + N 문제를 동시에 해결하는 놀라운 일을 간단한 방법으로 해결한 것입니다.
Q. 물음표는 무엇인가요?
A. 물음표에는 Team ID가 들어갑니다. 물음표의 개수는 쿼리의 IN 절의 파라미터 개수와 같은 의미이며, global, local 설정 시 줬던 size의 개수만큼 들어가게 됩니다. 저희는 현재 global, local 방식 모두 100을 줬기 때문에 100개의 Team 각각에 속해있는 Member를 조회하는 의미입니다. (지금은 2개뿐이라 2개만 들어간 것입니다.) 만약 100개가 넘은 Team의 개수를 조회하게 된다면 처음에는 100개를 조회하고 101번째 Team에 속하는 Member를 조회하는 시점에 쿼리문이 한 번 더 발생하게 됩니다.
Q. 적당한 사이즈를 고르는 팁?
A. 이 부분은 영한님이 저술하신 자바 ORM 표준 JPA 프로그래밍을 참조해주시기 바랍니다.
'Spring > Spring Data JPA' 카테고리의 다른 글
| Spring Data JPA - 상속(Inheritance) + 다대다(N:M) 관계 (0) | 2022.01.09 |
|---|---|
| Spring Data JPA - Self-Reference (0) | 2021.12.20 |
| Spring Data JPA - N + 1 문제 ② 해결 방법 (0) | 2021.12.02 |
| Spring Data JPA - N + 1 문제 ① (0) | 2021.11.29 |
| Spring Data JPA - Auditing (0) | 2021.11.28 |



